Why Being Indispensable Is Killing Your Data Career
The Hero Bottleneck

You think your job is safe because you are the only one who can untangle the legacy Airflow DAGs when they fail at 2:00 AM. You think you hold the keys to the kingdom because nobody else understands the silent data skew ripping through the customer ingestion pipelines.
You think you are indispensable.
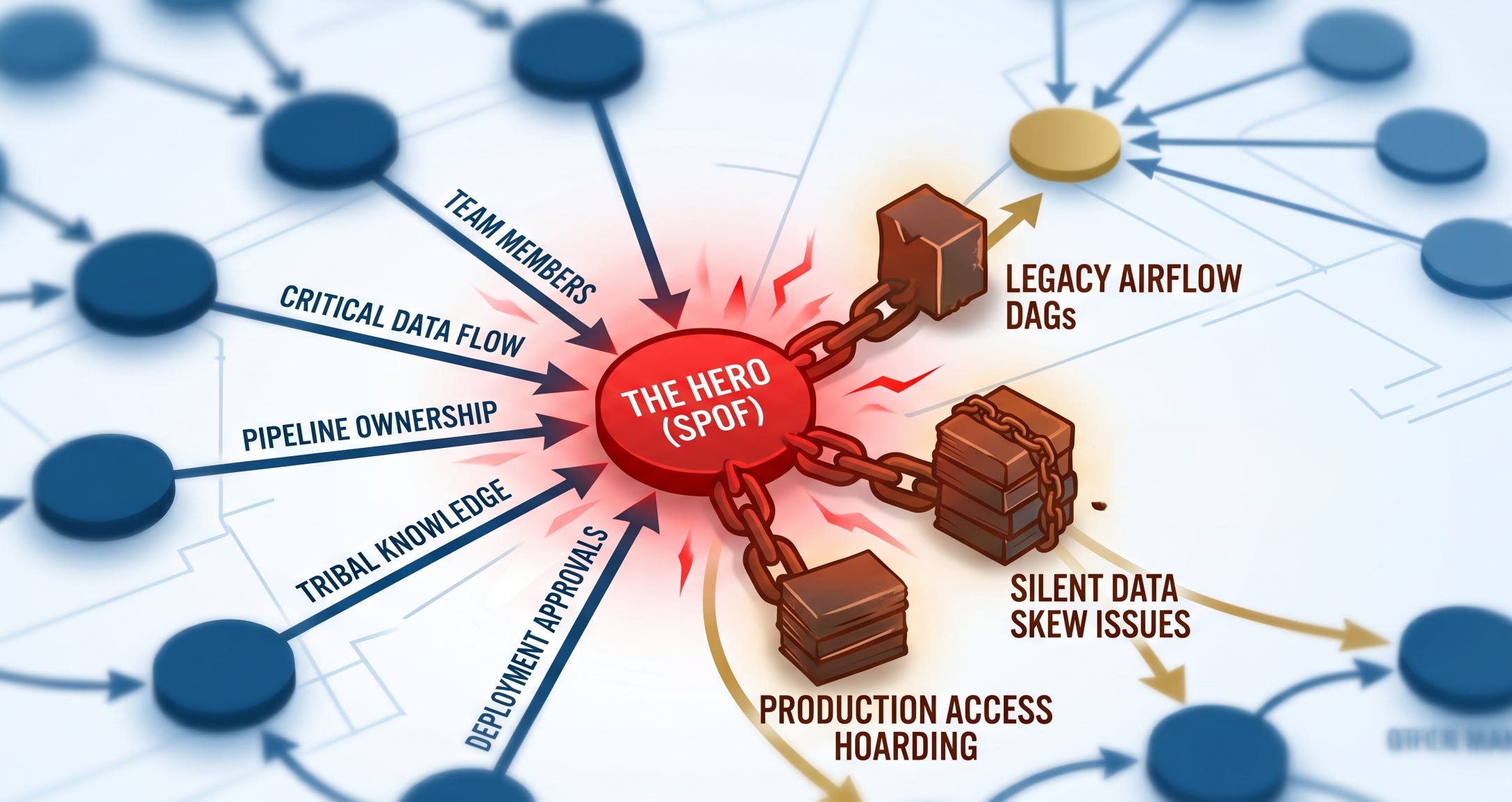
From where I sit, looking at the operational risks of this organization, you aren’t a hero. You are a Single Point of Failure (SPOF). You are a massive liability, and your “indispensability” is exactly why your career has flatlined.
For the first half of my career, I was exactly where you are. I was the wizard. I was the guy everyone called when the data infrastructure was bleeding out on the operating table. It felt like job security. When surplus cuts and layoffs rolled through the industry, my name was never on the chopping block because the business literally could not function without my hands on the keyboard.
But when I wanted to scale my impact, whether that meant stepping into a strategic architecture role or moving into leadership, I hit a brick wall.
Middle management is inherently terrified. If they promote the wizard, who is going to keep the fragile, duct-taped pipelines running?
This is the reality of the “Zone of Excellence.” It is a trap. If you build systems that require your heartbeat to function, you are building your own cage. Let me show you exactly what that looks like, the political warfare required to buy your way out, and how to engineer a production-grade escape route.
The Anatomy of the Cage: Keeping the Wheels on the Bus
People outside the trenches look at fragile, convoluted legacy pipelines and assume they are the result of ego or “Resume-Driven Development.” They assume the wizard built a hyper-complex system just to look smart, stringing together Kafka, Spark, and custom microservices when a simple cron job and Postgres would have worked.
The truth is much uglier. Wizards build cages unintentionally.
Fragility isn’t born from ego; it is born from pure survival mode. In the real world, the wizard is usually a one-person team (or maybe a stretched-thin squad of three) trying to service an entire enterprise organization. You are just trying to keep the wheels on the bus while the bus is barreling down the highway at 80 miles per hour.
You take the fast path because it is the only path. You duct-tape a fragile ingestion script together, skip the error handling, ignore the data quality checks, and hardcode the credentials because you have five other critical fires burning simultaneously. You do what you have to do to get by and move on to the next disaster.
But over time, those temporary, survival-mode fixes harden into permanent infrastructure. The business scales, the volume of data 100x’s, but the architecture remains the same hacked-together script you wrote at 3:00 AM three years ago. And suddenly, you are the only one who knows which string to pull to keep the entire reporting layer from collapsing.
The Capacity Trap: The Unfunded Mandate
Here is where standard engineering advice fails you. Blog posts and textbooks will tell you to “just build immutable infrastructure” or “just implement data contracts.”
That advice is an insult to a drowning engineer.
You already know the architecture is garbage. You know what a production-grade system looks like. The problem isn’t a lack of knowledge or discipline; it is a lack of capacity. You are trapped in a system where middle management treats technical debt cleanup as a “nice to have,” while demanding 100% of your sprint capacity for shipping new features.
Asking you to rebuild the plane while you are flying it is an unfunded mandate.
If you want the runway to build Anti-Fragile systems, you have to force the business to pay for it. You cannot walk into your VP’s office and talk about “YAML-driven metadata frameworks.” They don’t care. You have to weaponize “Code to Cash.”
You walk in and say: “This fragile legacy pipeline costs us 15 hours of engineering time a week in manual restarts and debugging. At our blended hourly rate, that is a $75,000 annual bleed in wasted operations, not to mention the SLA risks to our cybersecurity dashboards. Give me a two-week sprint to implement an automated configuration framework, and I will hand you back $75,000 in operational capacity to put toward the new roadmap.”
You don’t ask for permission to engineer your escape. You extort them with their own operational losses.
The Endgame: Staff IC vs. Director Leadership
Let’s clarify the objective. “Engineering your own obsolescence” isn’t just about moving into management. Not every senior engineer wants to be a Director, and they shouldn’t have to be.
But whether you want to be a Director leading a blended team, or a Principal Engineer architecting cross-domain enterprise systems, the prerequisite is exactly the same: You cannot scale your impact if you are handcuffed to a single point of failure.
The Senior Engineer (The Hero): Scope is capped by the specific pipelines they manually babysit.
The Principal/Staff Engineer (The Architect): Scope spans the entire enterprise. They don’t manage people; they manage systems.
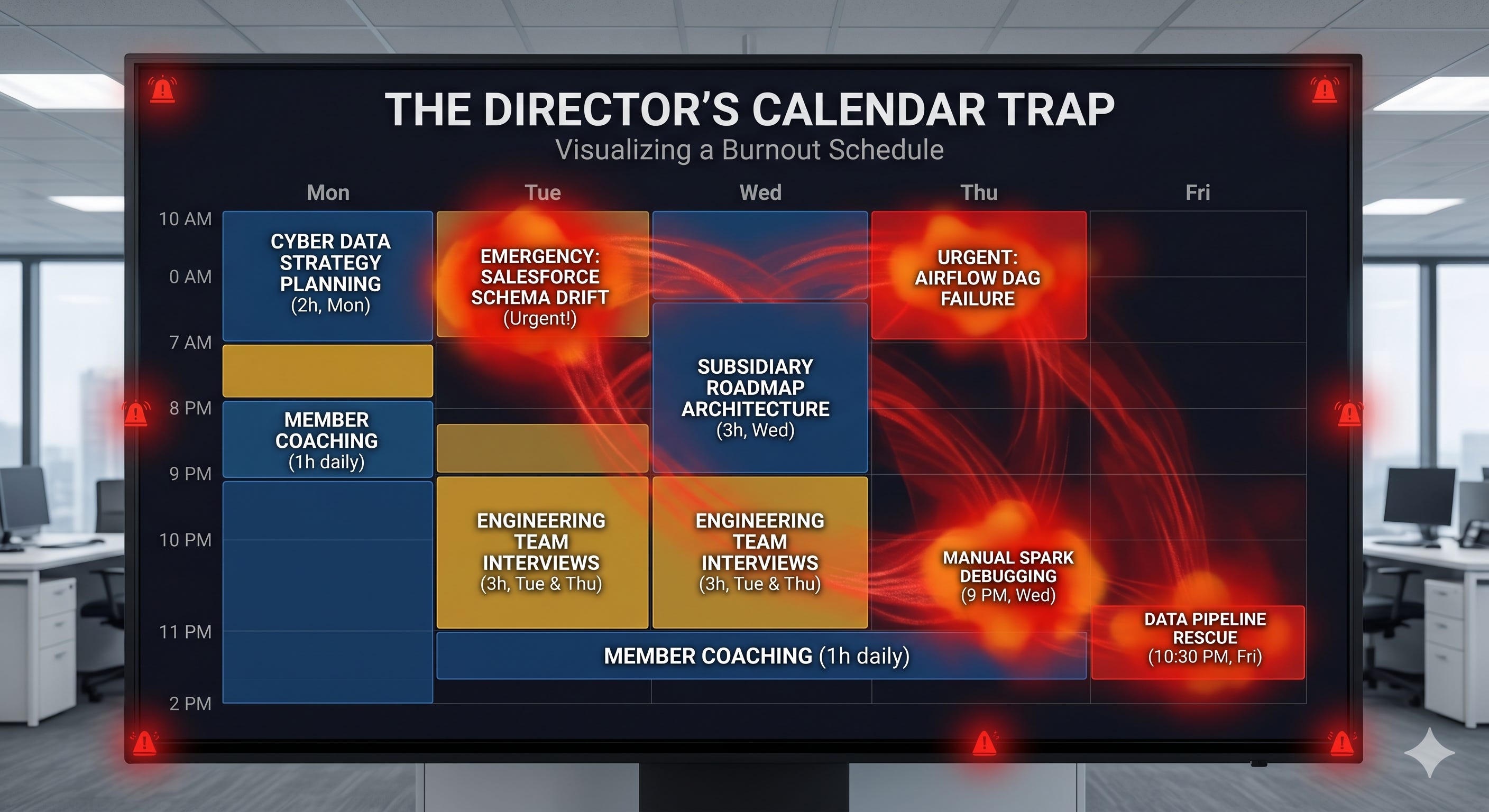
If you want the Principal title, or the Director title, your hands have to come off the keyboard for routine operations. If you drag your IC chains with you, the facade will crack, and the fallout will be spectacular.
The Breaking Point: The Cost of Missing the Room
I learned this the hard way. When I finally broke through and secured a Director position, my mandate was massive. I was architecting the data strategy for an arm of the business that owned multiple subsidiaries, leading data initiatives that fed directly into our cybersecurity threat detection, and hiring a blended engineering team.
But because I hadn’t built proper abstraction layers, I couldn’t hand off my legacy systems. At 10:00 PM on a Tuesday, I was still an Individual Contributor.
My breaking point wasn’t a technical glitch. It was a massive, humiliating leadership failure masquerading as an IT emergency.
I was so elbow-deep in untangling legacy Python scripts that I missed the strategic cross-functional steering meetings. Because I was down in the weeds, I missed the discussions about a massive, enterprise-wide architectural overhaul to our upstream Salesforce environment.
I didn’t find out about the schema changes until three weeks prior to deployment.
The result? Absolute chaos. My failure to act as a Director triggered a brutal fire drill. I had to force my brand-new data engineers to drop everything, work grueling hours, and desperately revamp and test massive chunks of our Salesforce ingestion layer. I thought being a hands-on hero protected my team. Instead, my inability to let go of the keyboard almost took down our executive reporting layer and burned out my new hires before they even got comfortable.
When the Director is acting like a janitor, nobody is steering the ship.
Building Anti-Fragility: Engineering Your Escape Route
If you want to survive the transition into enterprise architecture or leadership, you must systematically dismantle the survival-mode infrastructure you built.
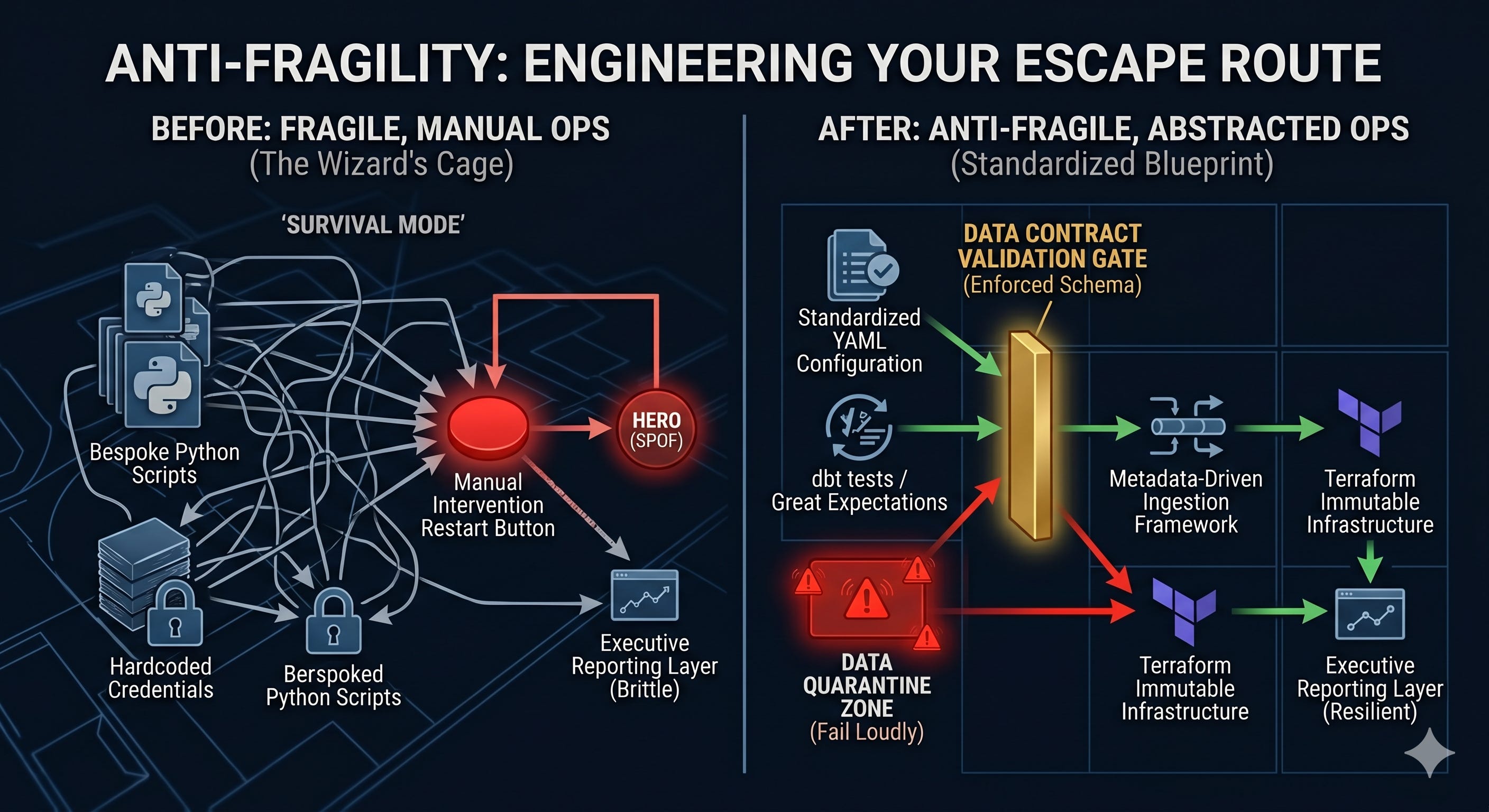
1. Enforce Upstream Contracts (The Real Guardrails)
Generic CI/CD advice won’t save you from a major Salesforce overhaul. Real guardrails are built around data contracts and schema validation.
Stop letting your pipelines blindly ingest whatever upstream applications spit out. Implement hard schema contracts at the ingestion layer. If a rogue dev drops a column, renames a primary key, or changes a data type, your pipeline should not silently ingest the nulls and corrupt the executive dashboard. It should fail loudly at the gate, preserve the last known good state, and instantly alert the team via automated routing. You stop the bleeding before it enters the warehouse.
2. Standardize the Blast Radius
“Abstracting complexity” is a fluffy buzzword. The trench reality is standardizing your blast radius.
When you have a small, scrappy team, every pipeline is a bespoke snowflake. To step away, you must enforce brutal standardization. Junior engineers should not be writing custom ingestion logic from scratch. They should be managing configurations. Build metadata-driven ingestion frameworks where a new data source is added by updating a YAML file, not by writing 500 lines of custom Python.
3. Kill the Console (Immutable Operations)
If you or your team have to log into a cloud console to manually restart a cluster, tweak a memory parameter, or manually execute a DAG when a job fails, your system is already broken.
Everything must be deployed via Infrastructure as Code (IaC). Terraform is the baseline. If the primary cluster crashes, the new hires shouldn’t need a Loom video from you explaining how to rebuild it. They should trigger a pipeline that spins up an exact, immutable replica from the repository.
The Verdict: Code to Cash
The industry doesn’t need more heroes. We don’t need more wizards hoarding knowledge to protect their paychecks. We need engineers who understand how to translate code into cash.

If you are fighting for a promotion to Staff or Director, stop proving that the team can’t survive without you. Use the unit economics of your own technical debt to extort the runway you need. Then, build a system so robust, so heavily standardized, and strictly contracted that you could walk away tomorrow and the business wouldn’t miss a beat.
Stop being the hero. Start engineering the system to survive without you.
About the Author
If you are a veteran engineer feeling the walls of the Wizard's Cage closing in, do not wait for a layoff to wake you up. Join the Gambill Data Coaching Program. We do not do "Happy Paths." We do production-grade reality.
Not ready to jump into the structured program? Join me for more insights on YouTube and LinkedIn!